RFM Segmentation Using BigQuery - Part 2

Advanced Purchasing Behaviour Segmentation with BigQuery ML
Intro
This blog post is the second part of our three-part Data Activation Series, where we’re exploring how to leverage customer data effectively using BigQuery and machine learning techniques. In this series, we aim to empower marketers and analysts with practical methods to segment and activate their customer base based on purchasing behavior, leading to more personalized and impactful marketing strategies.
Our goal is to show you how to go from raw data to actionable insights - and finally, to activate these insights in marketing platforms like Google Ads. By the end of the series, you’ll be equipped to turn your first-party data into tailored campaigns that reach the right audience with the right message, at the right time.
In this post, we’ll cover the following steps and tools:
-
Set Up Data: Prepare your RFM dataset in BigQuery, ensuring it includes metrics like Recency, Frequency, and Monetary value.
-
Create a K-Means Model: Leverage K-means in BigQuery ML to identify clusters of customers with similar purchasing behaviors. Unlike traditional segmentation, K-means clustering groups customers based on patterns across multiple metrics allowing us to uncover more advanced segments.
-
Evaluate and Interpret Clusters: Assess the effectiveness of the ML model and analyze the resulting clusters, with a focus on interpreting centroid values to gain insights into distinct customer segments.
-
Develop Targeted Strategies: Based on the cluster insights, outline specific marketing strategies tailored to each segment’s purchasing behavior.
Tools Needed:
- BigQuery: For data storage, preparation, and processing.
- BigQuery ML: For building and evaluating the K-Means clustering model.
By the end of this post, you’ll have a solid understanding of how to use K-Means clustering to segment audiences based on purchasing patterns and lay the groundwork for activating these segments in marketing campaigns.
Why K-Means Clustering?
In our previous post RFM Segmentation Using BigQuery, we demonstrated how to segment customers based on purchasing behavior using the NTILE function in BigQuery. While this approach helped us categorize customers, NTILE has limitations, especially for more complex segmentation.
NTILE creates equal-sized groups based on a single metric (Recency, Frequency, or Monetary value), which is useful for broad segmentation but can overlook key interactions between these metrics. By isolating each metric, NTILE may group customers with very different purchasing behaviors into the same segment if they score similarly on just one measure. For instance, a customer who makes frequent low-value purchases could end up in the same frequency-based segment as a customer who makes infrequent, high-value purchases, simply because both customers have made a similar number of transactions.
That is why we want to improve our segmentation approach by using K-means clustering with BigQuery ML. Unlike NTILE, K-means is an unsupervised machine learning algorithm that considers multiple dimensions at once. It identifies clusters based on natural groupings across all selected metrics, revealing more complex, multi-dimensional patterns in the data. For example, K-means can distinguish between high-frequency, high-spending customers and those who spend a lot but purchase infrequently - insights that NTILE might miss.
Setting Up K-Means in BigQuery ML
Step 1: Preparing the Data in BigQuery
To set up your data for K-means clustering, we’ll continue using the RFM dataset structure from the last post. This code snippet identifies the recency, frequency, and monetary values for each user, following the same conventions.
WITH transactions AS (
SELECT
*
FROM
`project.dataset.table`
WHERE
event_name = 'purchase'
),
rfm AS (
SELECT
user_pseudo_id,
DATE_DIFF(CURRENT_DATE(), MAX(PARSE_DATE('%Y%m%d', event_date)), DAY) AS recency,
COUNT(DISTINCT ecommerce.transaction_id) AS frequency,
SUM(ecommerce.purchase_revenue) AS monetary
FROM
transactions
GROUP BY
user_pseudo_id
)
SELECT
*
FROM
rfm
Step 2: Creating the K-Means Model
Using this prepared RFM dataset, we can now create the K-means model. One of the benefits of using BigQuery ML is how straightforward it is to set up a machine learning model with just a few lines of SQL code. With BigQuery ML, we don’t need extensive configurations or complex scripts. Here’s the code to create a K-means model for our RFM data:
CREATE OR REPLACE MODEL project.dataset.rfm_kmeans_model
OPTIONS(
model_type='kmeans',
num_clusters=6,
standardize_features=true
) AS
SELECT
recency,
frequency,
monetary
FROM
rfm
Explanation of Parameters
The OPTIONS clause is where we specify the key settings for our model. Let’s break down each parameter here:
- model_type=‘kmeans’: This tells BigQuery ML to use the K-means clustering algorithm.
- num_clusters=6: This parameter defines the number of clusters we want the model to create. Choosing the right number of clusters often requires experimentation and can depend on your business needs. In this case, six clusters give us a balance between granularity and interpretability for our RFM segmentation.
- standardize_features=true: Standardization scales each feature (Recency, Frequency, Monetary) so that they have a similar range, typically by transforming them to have a mean of 0 and a standard deviation of 1. This is important in clustering, as it ensures that features with larger values (like monetary) don’t dominate the clustering process. By standardizing, we allow each feature to contribute equally to the formation of clusters.
With these settings, BigQuery ML automatically handles the clustering process, and in just a few lines of code, we have a fully trained K-means model ready for evaluation and analysis.
Step 3: Evaluating the Model
After training the model, go to the BigQuery console, select your K-Means model under the Models section, and navigate to the Evaluation tab to assess its performance.
Understanding the Evaluation Metrics
In the Evaluation tab, you’ll find key metrics to assess the model’s clustering effectiveness:
- Centroids: Centroids represent the center of each cluster in the multidimensional space defined by your features (recency, frequency, monetary). They help in interpreting the characteristics of each cluster.
- Davies–Bouldin Index (DBI): The DBI measures the average similarity between clusters. A lower value indicates well-separated, more defined clusters. Our model has a DBI of 1.1128, suggesting reasonably distinct clusters for marketing purposes.
- Mean Squared Distance: This metric indicates the variance within clusters. A lower mean squared distance (ours is 0.9133) signifies that data points are close to their respective cluster centroids, indicating tight clusters.
Interpreting the Clusters
With our K-Means model evaluated, it’s time to dive into the clusters it has generated. Understanding these clusters is crucial for marketers aiming to tailor strategies that resonate with specific customer segments. Since we used standardize_features=true, the centroid values for Recency, Frequency, and Monetary represent standardized scores rather than actual units like days or currency. This means each centroid shows how high or low the cluster’s average is for each metric relative to the overall dataset, rather than absolute values. Let’s explore which clusters hold the most interest and why, and how they can drive marketing effectiveness.
Here’s a breakdown of the key clusters and suggested strategies:
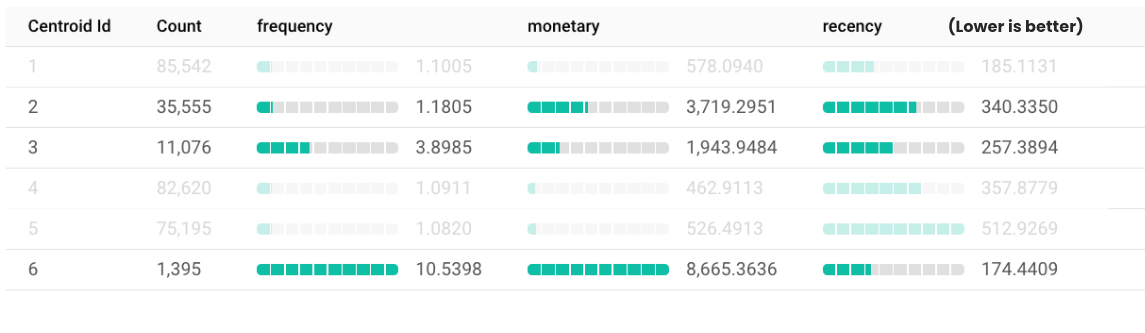
Cluster 6: The Elite Loyalists
Cluster 6 represents a small but immensely valuable group of 1,395 customers. These individuals show high scores for both frequency and monetary value, reflecting frequent purchases and significant spending. Their recency score is relatively low, indicating they have engaged with your business recently.
These customers are the perfect example of loyalty and high engagement - they not only purchase often but also contribute substantially to revenue. To maximize the value from this cluster, consider implementing personalized marketing strategies, such as exclusive offers, early access to new products, and targeted communications. They may also be ideal candidates for VIP or loyalty programs that recognize and reward their commitment to your brand. Additionally, because of their strong engagement, these customers might be good candidates to exclude from brand campaigns, as they are likely to convert on their own without additional prompting, allowing you to allocate budget more efficiently.
Cluster 2: High-Spending Occasional Buyers
Cluster 2 includes 35,555 customers who, despite purchasing infrequently, show high scores in monetary value. This suggests that while they don’t shop often, they spend a substantial amount when they do. However, their relatively high recency score implies they haven’t engaged with your brand in some time. This cluster presents a significant opportunity, as these customers have demonstrated a willingness to spend but lack regular engagement. By understanding what motivates their large purchases, you can tailor strategies to encourage more frequent shopping. Re-engagement campaigns that highlight high-value products or offer incentives for repeat purchases could be effective in turning these occasional high spenders into more consistent customers.
Cluster 3: Moderate Spenders at Risk of Churning
Cluster 3 comprises 11,076 customers with moderate purchasing behavior. They have mid-level scores for both frequency and monetary value, indicating some brand familiarity and satisfaction, but their relatively high recency score suggests they haven’t engaged in a while.
These customers are at a critical juncture, as their purchasing history shows some affinity with your brand, yet recent inactivity could signal a decline in interest. Retention strategies are essential here—personalized communications reminding them of the value they found in your products, special offers to entice them back, or engaging them through new channels like your app could rekindle their interest.
The Silent Majority: Clusters 1, 4, and 5
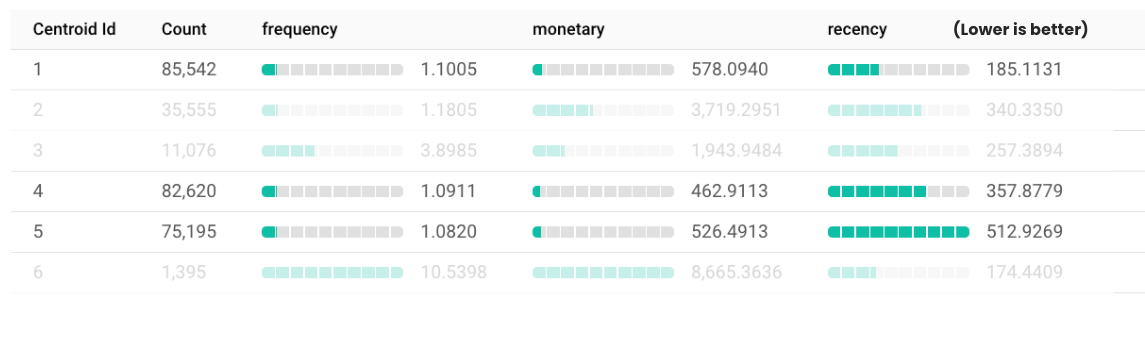
Clusters 1, 4, and 5 represent the largest segments, collectively encompassing over 243,000 customers. These customers have low scores in both frequency and monetary value, showing limited engagement. While they may not contribute significantly to revenue on an individual basis, their sheer numbers mean they collectively hold substantial potential. Small increases in engagement or spending across this group can lead to meaningful gains. Broad marketing strategies, such as win-back campaigns or educational content that builds brand awareness, can be effective. Additionally, further segmentation within these clusters based on demographics or preferences could allow for more targeted and effective marketing efforts.
Conclusion: Turning Insights into Action
Transitioning from NTILE segmentation to K-Means clustering has provided deeper insights into your customer base. By identifying and understanding key clusters, you can tailor your marketing strategies to meet the specific needs and behaviors of each segment. This approach moves beyond one-size-fits-all marketing, enabling you to connect with customers on a more personal level and drive better business outcomes. In our next and final installment of this series, we’ll take these insights a step further. We’ll explore how to activate one of these clusters in Google Ads, turning data-driven segmentation into actionable marketing campaigns. Stay tuned to discover how you can leverage these insights to drive growth and outpace your competition.
Ready to transform your customer segmentation and boost your marketing ROI? Contact us today to discover how we can help you activate your first-party data and personalize your marketing campaigns with algorithms for faster growth.